temps de la publication #
L’Internet-bibliothèque, une circulation de contenus sans limite #
« L'édition peut être comprise comme un processus de médiation qui permet à un contenu d'exister et d'être accessible. On peut distinguer trois étapes de ce processus qui correspondent à trois fonctions différentes de l'édition : une fonction de choix et de production, une fonction de légitimation et une fonction de diffusion. »1 (Vitali-Rosati M. et Epron B. L'édition à l'ère numérique, 2018)
Internet était à l'origine considéré comme un ensemble de documents liés2, ce qui a considérablement modifié nos habitudes d'écriture, de publication et de lecture. La numérisation consiste à porter et représenter des documents physiques et/ou leur contenu sous forme numérique. C’est la pratique d’édition numérique la plus ancienne que l’on puisse trouver. La première initiative de numérisation émane de la télégraphie électrique3 où la transmission de l'information venait de s'affranchir des obstacles physiques. L’impulsion individuelle de Michael Hart, en juillet 1971 qui numérise la Déclaration d’indépendance des Etats-Unis4 emmène la question de la numérisation à l’imprimé . Les moyens techniques dont il dispose à l’époque sont encore limités. Il retranscrit de manière dactylographique le texte, les caractères sont uniquement en majuscule et le texte final faisant 5 kilo-octet. Ainsi numérisé, le premier « livre électronique » est mis en dépôt sur un serveur de l’ARPANET5 et Hart informe par message de son existence. Suite à cela, six personnes téléchargent le fichier. Le projet a ensuite été dopé par l’arrivée du Web en 1991. Des bénévoles de plus en plus nombreux l’ont dès lors alimenté en littérature classique tombée dans le domaine public. Le web utilisé par Hart pour diffuser le Projet Gutenberg repose sur une association du Langage Sémantique (HTML), qui permet la structure logique des contenus et l'utilisation de liens hypertextes ; et du protocole de communication (HTTP) qui permet d'accéder à ces documents via Internet. L’Hypertexte lui se définit comme un système de présentation de l'information textuelle qui permet de passer d'un document à un autre au moyen de liens sémantiques préétablis et activables (liens hypertextes).
Aujourd'hui encore, Internet conserve la logique associée au contenu dans sa forme et sa finalité, ainsi que dans ses méthodes de conception et de production. Depuis les années 2000, de plus en plus d'outils et de services éditoriaux applicatifs sont apparus dans le domaine des réseaux, ouvrant la perspective d'écrire, d'accéder et de s'approprier ces contenus. En 2008, le projet Gutenberg a dépassé la valeur symbolique de 25 000 livres numérisés. D'autres bibliothèques numériques avec des ressources beaucoup plus conséquentes se sont également jointes à cette question, telles que Google Books6 et Gallica7 par exemple.
La décennie suivante tente de connecter les savoirs et d'orienter mieux l’individu dans son contexte (Web 3.08) alors conceptualisé autour de la curation — compréhension et exploitation des données. Le Web se transforme, « le web est une base de données géante, divisée en groupes avec une multitude de liens entre eux pour croiser les données. Intégration des metadata dans les ressources accessibles partout, à tout moment et sur n’importe quel support »9. L’utilisateur est définitivement devenu acteur, organisant et créant du contenu. Les sites sont orientés sur une personnalisation poussée de leurs contenus et interfaces (Cookies10, filtres personnalisés, recommandations). Le Web 3.0 ajoute à la relation entre contenus et individus la relation avec les machines. Comme énoncé précédemment les métadonnées ainsi que le travail de structuration et de balisage ont permis un travail automatisé et algorithmique du traitement de l’information. Les machines devenant des instances en capacité de traiter, indexer, éditer des contenus. Il privilégie l’efficacité, l’immédiateté et la masse d’informations. Les éléments paratextes sont ici assimilés à des métadonnées ( « méta-texte »11). Ces dernières années, les systèmes informatiques avec des méta données volumineuses et interdépendantes sont devenus plus importants que les données elles-mêmes. Le monde dans lequel nous vivons est modelé sur les métadonnées, et les ordinateurs peuvent utiliser ces informations pour comprendre la relation entre les humains et les machines. Par conséquent, la collecte et l'utilisation des métadonnées est une question centrale pour toute organisation qui doit traiter des archives12.
La diffusion de contenus fait maintenant preuve d’ubiquité, tout contenu peut être à présent dupliqué, transféré, sauvegardé. Tout ceci initié par le travail de Michael Hart avec le Projet Gutenberg et qui sera secondé par les « Wiki13 ». Wikipédia est une partie importante du processus de recherche et de ce fait de la diffusion de contenus. Avoir plus de références permet de conforter le statut de Wikipédia comme outil de référence, notamment grâce à sa qualité Open source14. Parce que tout le monde peut éditer Wikipédia, la communauté a élaboré une stratégie pour garantir la qualité des informations dans ses articles : l'ajout de référence à des sources fiables pour permettre aux lecteurs de Wikipédia de « vérifier » l'information. Cette stratégie permet à la communauté de travailler efficacement en vue d'atteindre la vision de Wikipédia : réunir et offrir la somme de toutes les connaissances humaines.
Les lecteurs et les éditeurs qui ne se sentent pas à l'aise avec une information trouvée dans un article peuvent y inclure la mention "référence nécessaire". Cette mention fait office de traceur et permet le référencement de toutes les demandes. Des milliers d'articles sur Wikipédia manquent de références ; 83 000 articles de la Wikipédia francophone en manquent. Le scripteur devient donc collectif tant le lecteur peut devenir actif dans l’immédiateté de l’information dans des discours co-constitutifs.
« Les bibliothécaires pourraient proposer des cours sur le développement des compétences informationnelles durant lesquels Wikipédia servirait de support pédagogique. L’encyclopédie pourrait par exemple ouvrir une discussion autour de l’importance des sources et de leur référenciation, notamment lors de la rédaction de travaux universitaires. Un échange basé sur une mise en application concrète lors de création d’une page Wikipédia avec les étudiants. Cependant, les enjeux sont plus vastes que cela, car Wikipédia représente une culture éditoriale unique de par l’horizontalité de ses pratiques. »15
L’objectif aujourd'hui est d'ajouter une référence à n'importe quel article Wikipédia. Toute référence à une source fiable aide les lecteurs à travers le monde. Lorsque l’on ajoute une référence à un article, inclure le hashtag #1Lib1Ref dans le résumé de modification permet de suivre les participations. La campagne #1Lib1Ref se déroule 2 fois par an ː du 15 janvier au 5 .février et du 15 mai au 5 juin. Elle est soutenue par La bibliothèque Wikipédia, et un nombre important d'organisations Wikimedia partout dans le monde. Dans le cadre de cet événement, des bibliothèques de toutes sortes et de toutes tailles organisent des activités de promotion.
Discours rapporté, automatisation et réduction #
Il ne s’agit pas ici de faire un éloge non-équivoque à la capacité incroyable de diffusion et publication à l’ère Post-Internet car il est évident qu’une telle forme d’ubiquité et d'instantanéité pose à la fois un problème éthique et et un problème de sécurité. On le voit notamment avec la rétention et l’accumulation de données par les GAFAM16.
Le point crucial est ici la séparation entre le contenu textuel – ayant vocation à circuler, à s’échanger – et l’appareil qui, lui, est associé à un utilisateur particulier et peut dans cette mesure connaître ses habitudes, son histoire, la séquence de ses lectures etc. L’édition numérique pourra retenir beaucoup de choses sur la façon de lire d’un utilisateur : le temps passé sur chaque page, les sauts de chapitre, les retours en arrière, les passages répétés, les pauses de lecture et même l'attention du lecteur sur chaque partie du texte. Ils finiront par savoir qui les lit et qui les a déjà lus. En plus des multiples notes, traits de soulignement et signets que les lecteurs ont volontairement ajoutés, ces traces enrichiront le livre. Le tabou de notre culture qui nous empêche d'annoter ou de commenter les livres des autres peut enfin être levé, car les lecteurs peuvent décider à tout moment de l'expérience de lecture « riche » qu'ils souhaitent, le lecteur devient scripteur par annotations/citations/emprunts. De ce fait, l’ordinateur peut faciliter la consultation de points de vue opposés, et offre par conséquent une possibilité de synthèse et de critique de l’information.
Cette circulation et échange textuels en milieu numérique amplifient eux mêmes les conversations et la création d’autres contenus à partir d’emprunts, de citations et de liens. Comment écrire sans écriture pour révéler la fécondité de l’ordinaire ? Base de données, traitement de texte, identités cryptées : « vous pensiez recopier, répéter, plagier, vous vous pensiez englué dans le quotidien d’une écriture non-créative, vous en sortez pourtant renouvelé »17. Malgré les questions éthiques liées au plagiat, le rôle de l'opération de remplacement du déjà écrit est loin d'être secondaire. Il semble que ce genre d'opération soit au centre de nombreuses contributions génétiques et puisse asseoir des méthodes d'enseignement de l'écriture18.
Le « non-créatif » , le génie « non-original » d’après Marjorie Perloff dans unoriginal genius ne dénie pas le génie. Celui-ci peut être celui qui sélectionne au mieux les passages, copie les meilleurs mots, tout ça pour faire bouger le langage de façon Duchampien, le faire passer d’un endroit à un autre, créer un contexte totalement différent. Un ready-made littéraire. Le scripteur devient collectif : un singulier pluriel. L’auteur reste auteur par sa subjectivité et les choix éditoriaux qu’il opère. En prenant pour exemple la pratique du Designer Rémi Forte qui, par collecte de fragments littéraires à plusieurs échelles (Glyphe/Mot/Paragraphe) et par règles algorithmiques et sa subjectivité, va concevoir ces poèmes et les mettre en forme de façon sensible et précise avant de les publier.
De ce fait, que nous réservent les années 2020 ? Le Web 4.019 a bien entendu démarré, qu’entend-il bouleverser ? Des premières réponses existent, avec notamment le changement d’architecture avec l’émergence du « Cloud20 » et l’ouverture des standards (Open-source), l’utilisateur ne personnalise pas systématiquement, l’interface le fait pour lui de façon générative en analysant à partir des données récupérées. Internet est orienté sur l’interaction individus|objets tentant de faciliter l’usage et l'efficacité de l’objet avec la bonne action au bon moment. Bien sûr la question que pose le Web 4.0 est la sécurité des sources et des accès aux données, la capacité d’analyser les comportements, à les convertir en données. Comme l’explique Aline Scouarnec dans Digital Ressources Humaines : « Le web 4.0 comme il est présenté aujourd’hui pourrait restreindre notre liberté et nos chances d'évolution et d’innovation ». Mais le Web aujourd’hui peut être le théâtre de créations collectives, d’engagements, de modulations, d’interactions, d'expérimentations, toutes permettant un partage et une sensibilisation mutuelle des contenus et interrogations que propose le Web 4.0.
Écriture, lecture et édition, fongibles : nouvelles formes de l'édition numérique #
Abandonner le terme de « chaîne »21 au profit de celui de « système » : Les différentes étapes du processus de publication ne doivent plus être vues comme une séquence linéaire, mais comme un assemblage complexe, une synergie de composants en interaction dynamique, plutôt que linéaire les uns après les autres. Cette proposition s'appuie sur les remarques faites dans la partie précédente, notamment à travers de nouvelles méthodologies de travail que proposent les chercheurs, artistes et designers. Si la dernière décennie a été consacrée à la recherche d'alternatives libres et ouvertes aux logiciels fermés et propriétaires, alors dans le monde de l'édition (écriture, structuration, collaboration, synthèse), ce mouvement de soutien aux alternatives pourrait être dépassé. La notion de « système » introduit le fait que les outils ne doivent pas exécuter des fonctions les unes après les autres selon un processus linéaire, mais sont assemblés de manière cohérente afin de communiquer entre eux, entre autre de les désynchroniser afin de penser des systèmes cohérents et réfléchis intégrant le travail collaboratif. Une tâche ne répond plus à une action précise dans une programme donné mais peut elle peut répondre à une pluralité d’actions et préoccupations dans diverses programmes.
Ces systèmes doivent reposer sur des modèles dit de l’Open Access22, d’échanges est un modèle où les contenus sont librement consultables, placés sous licence Creative Commons BY23 et référencés avec un identifiant DOI24. Open source, ou code ouvert en français, désigne les possibilités de libre redistribution, republication, d’accès au code source et de création de travaux dérivés pour un programme ou logiciel informatique. Le tout permettant de mettre à jour, ou modifier le logiciel, l’outil, le contenu. Si la démarche « libre » est un projet humain et politique, celle de l’open source vise avant tout l’évolution technique. Il faut distinguer « libre » d'« open source ». Sont qualifiés de « libres » des logiciels ou des programmes qui répondent aux quatre critères suivants : « l’utilisation, l’étude, la modification et la duplication par autrui en vue de sa diffusion sont permises, techniquement et légalement »25.
Dans un projet numérique donné voulant se concevoir dans un modèle participatif/collaboratif, il est primordial de versionner et de diffuser au sein du système de gestion de versions Git26. Un commit est un enregistrement accompagné d’un message, cela correspond à un état d’un projet géré avec Git. Permettant à toutes personnes voulant travailler/ récupérer le projet de savoir le niveau de version et les modifications engagées dans cette version. Il s’agit ici de pallier des problèmes inhérents aux chaînes de publications plus conventionnelles, d’échanges de versions et de validation de contenu, de corrections. Cela permet à la fois de valider et de conserver l’historique de l’évolution du projet évitant de nombreuses passes entre les différents acteurs. Git permet de marquer chaque étape et permet d’identifier les acteurs qui interviennent et sur quels éléments. L’open source permet autant une amélioration du projet (corriger des bugs, changer l’aspect graphique…) que de récupérer les données à d’autres fins (traitements scientifiques de données par exemple). En d’autres termes, l’open source permet à la fois d'assurer une accessibilité pérenne d’un projet, sa mutation mais aussi de pallier certains logiciels/contenus propriétaires afin de se soucier au mieux d’une continuité sur l’expérience proposée à l’utilisateur. Ces systèmes modulaires que permettent les outils du développement web sont un nouveau vecteur de création et permettent à la fois une modularité quant aux acteurs de créations et leurs positionnements dans la chaîne, une pluralité de formats (objet imprimé, ePub27, PDF, site web...) et la capacité de rétroaction/édition au cours du projet. « Les logiciels dits « open source » sont appréciés pour leur robustesse et leur performance, des considérations pratiques qui sont souvent les seules à guider le développement logiciel. Le mouvement du libre porte avec lui des valeurs inaliénables qui promeuvent une réelle liberté. »28. L’open source et l’open access permettent un vecteur de création supplémentaire en rendant le projet réutilisable, modifiable, altérable pour d’utilisations autres que celui initié.
Permettre à tout à chacun l’accès aux données, technologies, outils numériques/de développement web, c’est permettre une prolifération de création aussi variée et innovante que possible. L’ère du post-internet offre donc des nouveaux modèles expérimentés par des ateliers, des startups, des maisons d’éditions libres et d’autres acteurs. Ces modèles tentent de changer les chaînes de création et distribution les rendant plus floues et hybrides dans leurs co-influences. Parfois elles en sont même unies. Rendant chaque acteurs à la fois interchangeables dans leur période d'action mais aussi bien présents tout au long de la chaîne.
La conception d’un livre peut se programmer et être automatisée avec des scripts tels que paged.js29, bindery.js30, html2print31, Fonio32 . Cette automatisation implique en effet d’autres manières de faire où les designers doivent accepter de ne plus mettre en forme leurs documents manuellement. La conception procédurale se rapproche plus de méthodes issues de la mise en page Web où la structure du contenu prime sur sa forme. Comme pour les métadonnées des images sur les réseaux, c’est cette nouvelle sémantique du texte qui devient centrale et même si les designers sont toujours responsables de la forme finale, ils adoptent de plus en plus un rôle d’architecte des contenus à travers le support.
On observe actuellement une réelle volonté d’interroger les processus de création visuelle, notamment parce que les quantités de contenu à gérer ne sont plus compatibles avec les méthodologies conventionnelles. Ainsi, le groupe de recherche PrePostPrint33 défend depuis 2017 une approche de la publication expérimentale, où un même contenu formaté avec les langages du Web (HTML/XML34) est susceptible d’être publié sous différentes plateformes et différents formats. PrePostPrint associe des designers graphiques qui expérimentent ce type de processus pour envisager une autre manière de concevoir les objets imprimés.
Dans une optique similaire, « Open Source Publishing dessine des mises en page et code avec des logiciels libres ou open source. Il s’agit d’abord de questionner nos pratiques avec ces médiateurs omniprésents que sont les outils numériques et les communautés dont ils sont issus. Alors que la matérialité de l’informatique s’efface derrière des interfaces «intuitives », le logiciel libre, par sa nature ouverte, invite à saisir l'épaisseur culturelle des formats, interfaces et usages. Splines spirographiques, filtres ImageMagick ou lignes de commande sont quelques-unes des rencontres qui ont changé notre manière d’appréhender le vecteur, le bitmap ainsi que la manière de construire et de partager nos propres outils. Mais pour ce qui est de la mise en page, nous nous retrouvons face à un dilemme cornélien: celui d’avoir à choisir entre d’un côté une approche essentiellement visuelle, incarnée par Scribus et InDesign, et de l’autre une approche intégralement programmatique incarnée par TeX, LaTeX, Context. »35 ou Pandoc36.
De cette façon, un support comme l’édition numérique pourrait amener les lecteurs à exiger pour la plupart des situations de lecture intensive avec les divers avantages qui font la supériorité du support numérique, à savoir l’ubiquité d’accès que donne le Web, l’indexation généralisée qui permet de retrouver rapidement une citation ou une note marginale, la facilité des opérations de citation et, surtout, le contact permanent avec un espace de lecture où tous les textes sont interreliés et peuvent entrer instantanément en résonance les uns avec les autres.
Iconographie #
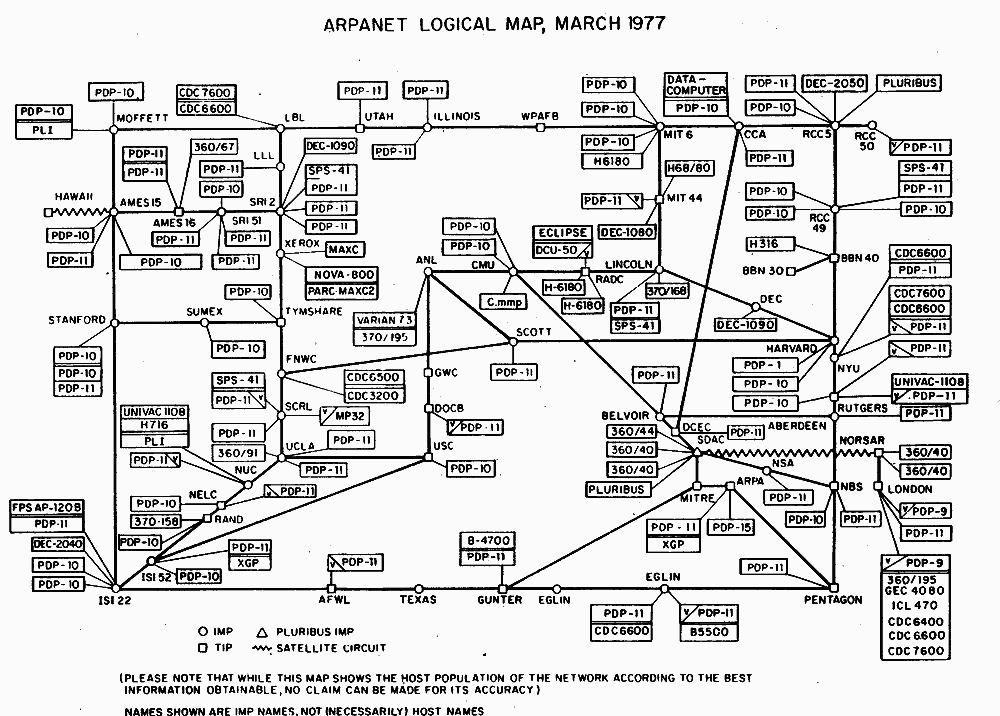
Carte logique du réseau, ARPANET, DARPA, 1977.

Déclaration d’indépendance des États-unis d’Amérique, eText#1, Project Gutenberg, Michael Hart, 1971.

The Federalist, eText#18, Project Gutenberg, Michael Hart, 1971.

Mémoire, Antoine Fauchié, écrit en MarkDown, 2019
Page Wikipédia d’Alexis Kauffmann, 2017 https://fr.wikipedia.org/wiki/Alexis_Kauffmann
Edition page Wikipédia d’Alexis Kauffmann, 2021 https://fr.wikipedia.org/w/index.php?title=Alexis_Kauffmann&action=history

Prototype of a virtual exhibition for the archives of Électre, staged by Antoine Vitez, Gabriele Cepulyte , 2018

Prototype of a virtual exhibition for the archives of Électre, staged by Antoine Vitez, Gabriele Cepulyte , 2018
(Trans)textual interfaces, Sylvain Julé, ANRT, 2015
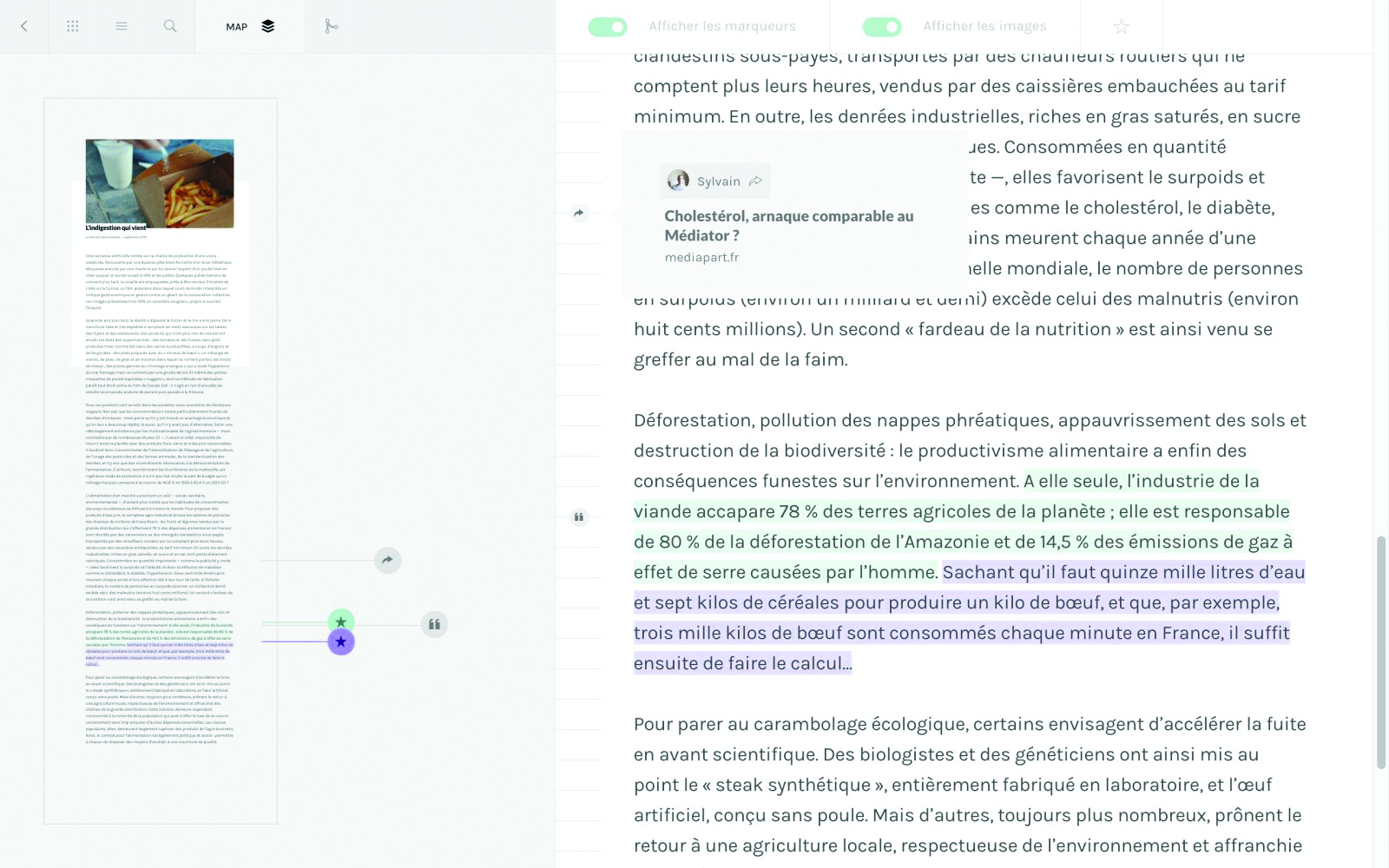
(Trans)textual interfaces, Sylvain Julé, ANRT, 2015
do•doc, un outil composite, atelier des chercheurs, 2017
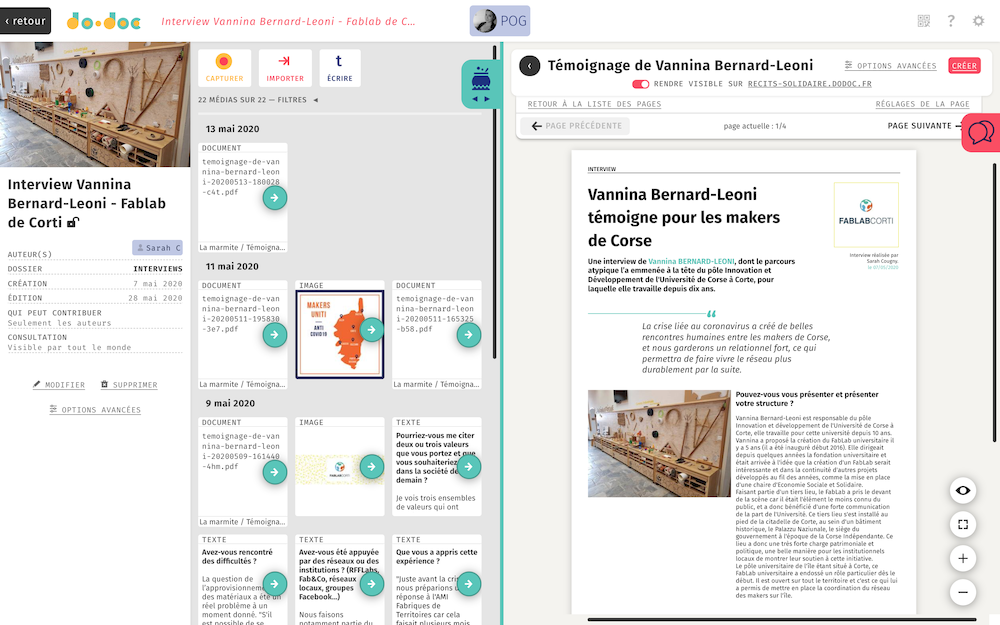
do•doc, un outil composite, atelier des chercheurs, 2017
-
Vitali-Rosati M. et Epron B. L'édition à l'ère numérique, 2018 ↩︎
-
Internet : entre écosystème de connaissances et instrumentalisation de l’information. Jean-Marc Meunier ↩︎
-
Commutation temporelle et de la numérisation de la transmission. Musso, Pierre. « II. Le système traditionnel des télécoms », Pierre Musso éd., Les télécommunications. La Découverte, 2008, pp. 24-37. ↩︎
-
eText #1 du Projet Gutenberg ↩︎
-
cf pp. ↩︎
-
Gallica est la bibliothèque numérique de la Bibliothèque nationale de France et de ses partenaires. En ligne depuis 1997, elle s’enrichit chaque semaine de milliers de nouveautés et offre aujourd’hui accès à plusieurs millions de documents. https://gallica.bnf.fr/edit/und/a-propos [Consulté le 08/10/2021 à 14h27.] ↩︎
-
C'est à la fois un outil de recherche intra-texte, de consultation de livres en ligne ou sur appareil mobile, de constitution de collections personnelles, et de téléchargement d'ouvrages libres de droits. C'est aussi une librairie en ligne via la boutique Google Play, un outil permettant de trouver où emprunter un exemplaire de livre en bibliothèque, et un fournisseur d'informations complémentaires (métadonnées) sur les œuvres. ↩︎
-
Selon le W3C, « le Web sémantique fournit un modèle qui permet aux données d'être partagées et réutilisées entre plusieurs applications, entreprises et groupes d'utilisateurs » ↩︎
-
http://www.duoexpertise.com/531-2/ [Consulté le 08/10/2021 à 14h42.] ↩︎
-
Un cookie est un petit fichier stocké par un serveur dans le terminal (ordinateur, téléphone, etc.) d’un utilisateur et associé à un domaine web (c’est à dire dans la majorité des cas à l’ensemble des pages d’un même site web). Ce fichier est automatiquement renvoyé lors de contacts ultérieurs avec le même domaine. CNIL. ↩︎
-
Antoine Fauchié, https://www.quaternum.net/2019/12/12/l-ecriture-du-papyrus-a-l-hypertexte/ ↩︎
-
L'édition à l'ère numérique Epron, Benoît (1977-.…). Auteur | Vitali-Rosati, Marcello (1979-.…). Auteur Édité par La Découverte - 2018. ↩︎
-
Un wiki est une application web qui permet la création, la modification et l'illustration collaboratives de pages à l'intérieur d'un site web. Il utilise un langage de balisage et son contenu est modifiable au moyen d’un navigateur web. C'est un logiciel de gestion de contenu, dont la structure implicite est minimale, tandis que la structure explicite se met en place progressivement en fonction des besoins des usagers. ↩︎
-
s'applique aux logiciels (et s'étend maintenant aux œuvres de l'esprit) dont la licence respecte des critères précisément établis par l'Open Source Initiative, c'est-à-dire les possibilités de libre redistribution, d'accès au code source et de création de travaux dérivés. Mis à la disposition du grand public, ce code source est généralement le résultat d'une collaboration entre programmeurs. ↩︎
-
Bruno Milia, Wikipédia, un ami au service d’une approche critique de la bibliothéconomie ↩︎
-
Google, Apple, Facebook, Amazon et Microsoft. ↩︎
-
Propos de Franck Leibovici dans L' émission La Suite dans les idées, « Uncreative writing » : pour une écriture sans écriture, le 02/06/2018 ↩︎
-
cf. Le rôle du mimétisme dans l'apprentissage chez l’enfant et Mimétisme comportemental René Girard-Association Recherches Mimétiques, « Psychologie - René Girard - Association Recherches Mimétiques » [archive], sur www.rene-girard.fr (consulté le 19 août 2021). ↩︎
-
Web 4.0 : l'Internet des objets et l'IA. ↩︎
-
« Le cloud computing est un modèle qui permet un accès omniprésent, pratique et à la demande à un réseau partagé et à un ensemble de ressources informatiques configurables (comme par exemple : des réseaux, des serveurs, du stockage, des applications et des services) qui peuvent être provisionnées et libérées avec un minimum d’administration. », L’informatique en Nuage, https:// www.figer.com, [en ligne], https:// www.figer.com/Publications/nuage. htm (Consulté le 24/10/21), National Institute of Standards and Technology ↩︎
-
Une chaîne éditoriale ou chaîne d'édition est la suite d'opérations (ou procédé industriel) par lequel un document rédigé par un auteur est transformé en document publiable et publié. Elle consiste à formater le document écrit, à élaborer des modèles de documents, et à effectuer les conversions de fichiers nécessaires. Elle s'occupe également du stockage et de la diffusion des documents. ↩︎
-
Le libre accès (anglais : open access) est la mise à disposition en ligne de contenus numériques, qui peuvent eux-mêmes être soit libres (Creative Commons, etc.), soit sous un des régimes de propriété intellectuelle. ↩︎
-
Constituent un ensemble de licences régissant les conditions de réutilisation et de distribution d'œuvres. ↩︎
-
Mécanisme d'identification de ressources, le but des DOI est de faciliter la gestion numérique sur le long terme de toute chose en associant des métadonnées à l'identifiant de la chose à gérer. Les métadonnées peuvent évoluer au cours du temps, mais l'identifiant reste invariant. ↩︎
-
https://fr.wikipedia.org/wiki/Logiciel_libre, Alexis Kauffmann. ↩︎
-
Git est un système de contrôle de version distribué gratuit et open source conçu pour gérer tout, des petits aux très grands projets numériques. ↩︎
-
EPUB (acronyme de « electronic publication », « publication électronique » en français, parfois typographié « ePub », « EPub » ou « epub ») est un format ouvert standardisé pour les livres numériques et proposé par l'International Digital Publishing Forum (IDPF). Il est fondé sur le XML. Les fichiers ont l’extension .epub. ↩︎
-
Louis-Olivier Brassard, Open source v. libre, https://journal.loupbrun.ca/n/066/ ↩︎
-
Paged.js is a free and open source JavaScript library that paginates content in the browser to create PDF output from any HTML content. This means you can design works for print (eg. books) using HTML and CSS. ↩︎
-
Bindery.js is a javascript library to create printable books with HTML and CSS. ↩︎
-
This little tool is a boilerplate, a minimal example to start a print project using HTML, less/CSS and Javascript/Jquery to design it. ↩︎
-
Fonio is a collaborative scholarly software allowing to build high quality static websites for teaching and research. It allows to make arguments through complex hypertextual structures, and to harness the richness of an enquiry's work by featuring bibliographic references, images, tables, videos, and interactive elements. ↩︎
-
L’initiative PrePostPrint est née d’un constat : les logiciels traditionnels de mise en page et d’édition sont figés, fermés, souvent coûteux, cloisonnés et cloisonnants, et parfois peu ergonomiques. Il est nécessaire d’envisager des technologies plus accessibles et conviviales, pouvant évoluer et s’adapter à chaque projet. Ainsi Sarah Garcin et Raphaël Bastide, deux designers graphiques aux pratiques numériquement libres, ont décidé de constituer un collectif dont les membres et les projets sont à géométrie variable. Rassembler les énergies déployées autour de la création et de l’usage d’outils alternatifs de publication, voilà l’ambition de PrePostPrint. ↩︎
-
XML, pour eXtensible Markup Language (langage de balisage extensible), est un langage de balisage généraliste recommandé par le W3C comme l'est HTML. XML est un sous-ensemble du langage SGML. Cela signifie que contrairement aux autres langages de balisages, XML n'est pas prédéfini, vous devez définir vos propres balises. Le but principal de ce langage est le partage de données entre différents systèmes, tel qu'Internet. ↩︎
-
« HTML2PRINT SANS SAUCE » in HTML SAUCE COCKTAIL, SAUCE Ã PART, OPEN SOURCE PUBLISHING – GRAPHIC DESIGN CARAVAN, February 15th, 2017, http://ospublish.constantvzw.org/blog/news/html-sauce-cocktail-sauce-a-part [consulté le 17/11/21 à 15:02] ↩︎
-
Pandoc est un convertisseur de documents balisés. Pandoc permet de convertir un fichier depuis un format de balisage vers un autre format de balisage, typiquement depuis le format de balisage léger Markdown vers le format de balisage moins léger HTML. Créé en 2006 par John MacFarlane, professeur de philosophie, Pandoc est souvent qualifié de “couteau suisse de l’édition”. Fauchier, Antoine, Fabriques de publication : Pandoc, 03/04/2020, https://www.quaternum.net/2020/04/30/fabriques-de-publication-pandoc/ [consulté le 10/11/2021 à 12:07] ↩︎